




 News
News


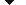
Encryption and Tokenization of International Unicode Data
May 2021 by Ulf Mattsson, CTO, Protegrity Corporation
Protecting the increasing use International Unicode characters is required by a growing number of Privacy Laws in many countries and general Privacy Concerns with private data. Current approaches to protect International Unicode characters will increase the size and change the data formats. This will break many applications and slow down business operations. The current approach is also randomly returning data in new and unexpected languages. New approach with significantly higher performance and a memory footprint can be customizable and fit on small IoT devices. We will discuss new approaches to achieve portability, security, performance, small memory footprint and language preservation for privacy protecting of Unicode data. These new approaches provide granular protection for all Unicode languages and customizable alphabets and byte length preserving protection of privacy protected characters. We will focus on UTF-8 since character encodings for websites 2020 reported that UTF-8 is used by 95.4% .
Unicode Code points for the Scripts can be stored in UTF-8 in one to four bytes
1) 128 characters (US-ASCII)
2) 1,920 characters Latin-script, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N’Ko alphabets.
3) Characters in common use, including most Chinese, Japanese and Korean characters**.
4) Less common CJK (The commonly used Hanzi/Kanji characters are in the "CJK Unified Ideographs").
Examples of Tokenization of Unicode
Token Fabric generated from input of Unicode Code Points
A fabric of intermediate tokens is created to increase the entropy of each final token. The blue tokens represent temporary results and the final token values are green:

Forward and backward chaining of tokens
The tokenization function can be based on randomized lookup tables or encryption. The chaining can add entropy via additional tokenization input to the tokenization process in each step. This example with short data is based on a two-character input-string “AA” that will generate the middle layer tokens that are temporary results and the final tokens are at the bottom layer. The tokens are chained forward and backwards to increase the entropy:

These are examples of European Scripts
Examples of languages with one to two bytes characters

These are examples of East Asian Scripts

Example of tokenizing five Japanese Scripts in an address label


Summary
We discussed an approach that is not returning tokenized data in new and unexpected languages. New approach with significantly higher performance and a memory footprint can be customizable and fit on small IoT devices. New approaches can achieve portability, security, performance, small memory footprint and language preservation for privacy protecting of Unicode data. These new approaches provide granular protection for all Unicode languages and customizable alphabets and byte length preserving protection of privacy protected characters.
